This is the first post in a three part series digging deeper into the emerging field of data science. The series aims to demystify data science using the first-hand knowledge of Sandfield’s resident data scientist, Mustafa Hasanbulli, who holds two PhD’s in mathematics and theoretical chemistry.
In this series, Mustafa will explain what data science is and what it isn’t, and show the value its methodology and insights can provide in making informed business decisions for forward-thinking companies.
Data science is one of the hottest topics in business today, but if we are honest, most people would struggle to define what it actually is.
The confusion is understandable - we weren’t given an official definition.
We have produced more data in the last five years than in the entirety of human existence.
We have produced more data in the last five years than in the entirety of human existence. By 2022, the digital universe will contain nearly as many digital bits as there are stars in the universe. In terms of money, the IDC predicts worldwide revenue for the big data and business analytics industry will be more than USD$260 billion.
A quick search for “data science” and “big data” on Google Trends shows the close correlation between these search terms and how they are perceived.

The inevitable rise of big data has also triggered all the interest and popularity of data science, and ultimately a number of misconceptions about it. This means a number of businesses may not realise the powerful potential that data science holds for them in gaining an edge on their competitors.
Where did it come from?
The term “data science” was first used by Danish computing science pioneer Peter Naur in 1960 as a substitute term for computer science.

Its real popularity started gaining a steady increase about five years ago, with new emerging technologies able to harvest information from large data sets.
With these technologies, the term ‘data science’ was reintroduced with a fresh meaning - a new hybrid field that would tap into the power of both mathematics and computer science.
While data science as we know it is a new field, the science part of it has been around for centuries. We all learned about the scientific method in school - a systematic way of learning about the world around us and answering questions. We were taught to come up with a hypothesis, collect data, test our hypothesis and, based on the results, form a conclusion.
Data science has intertwined these scientific foundations with analytical areas such as statistics, data analysis, and BI analytics into what we know as data science today.
Scientific Method

The term “data scientist” was first used in its new context by Jeff Hammerbacher (former head of data for Facebook) and D.J. Patil (former chief data scientist for the Whitehouse) to describe a new job title. They were looking for likeminded people skilled in mathematics, statistics, computer science, machine learning and business acumen. Demand for this hybrid skill set continued to grow, academics started to migrate from academia into the business world, bringing their scientific methodology into the data industry.
Why does this role exist?
90% of the world’s data is unstructured, it has no shape or order - and it is growing fast. As a result, the decision-making process is getting more difficult and complex than ever. In most cases, there are always hidden variables that can affect the result of any decision made. Relying solely on domain expertise is not enough anymore.

The advent of big data and technologies that are invented around it require the people that work with it to have a unique combination of skills. They need to know advanced mathematics and computer science so that they can translate mathematical methods to computer language.
This skillset combination enables them to make use of this unstructured data, incorporating it into the business processes by augmenting existing solutions and gaining unique insights that give them an edge over competitors.
‘The Netflix Prize’
One of the most famous examples of data science in action was a competition held by Netflix.
In 2006, the streaming giant announced ‘The Netflix Prize’ - an open competition for US$1M for a collaborative filtering algorithm that would increase the accuracy of predicting user ratings for films, based on previous ratings without any other information about the users or films by 10%. It took a group of mathematicians and computer scientists three years to reach the goal.
We have come a long way since then. We have more data, but better infrastructure with incredibly powerful computers.
All we needed was people to connect the two.
People skilled enough to know the details of mathematical methods, with the knowledge of how the infrastructure worked. This is one of the primary reasons why we have data scientists. They are the ones able to see opportunities of marrying mathematical methods and computer technology together, creating efficiencies and insights that take a lot less than three years to reach.
The methodology in the madness
The scientific method is a well-structured methodology, it is engraved into the very foundation of scientists.
When the shift from academia to the industry started, it was necessary to introduce a similar methodology that would be the golden standard in the data science industry.
Such a methodology was first introduced in 1996; CRoss Industry Standard Process for Data Mining or CRISP-DM. Over the years, this methodology went through a few reviews but its foundations have not changed. The whole process can be summarised by the cyclic process depicted below:
- Business Understanding: This is the step that defines the business problem we would like to solve
- Data Understanding: It is important to understand the nature of the available data and decide if other data sources are necessary to produce a valid solution
- Data Preparation: In this step, we gather the data from their sources, then cleanse and augment it into a shape that is used for modelling
- Modelling: Depending on the business problem at hand, we try different modelling techniques that would represent the data in the best possible way
- Evaluation: It is important to measure the accuracy of the model by comparing it to the actual results
- Deployment: This is the final step of the CRISP-DM process where the trained model is pushed into a production environment e.g. an app or as part of a bigger software solution
What Data Scientists
spend the most time doing
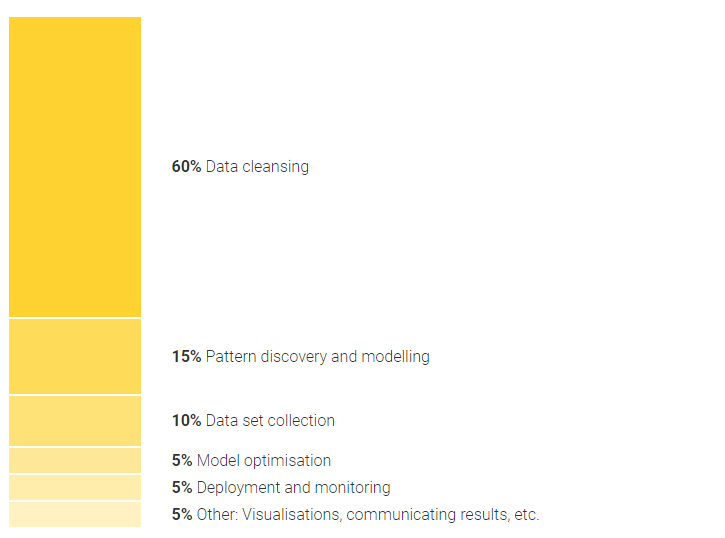
Data analyst vs data scientist
One of the reasons it can be difficult to grasp what data scientists do is the fact that we tend to use its job title very loosely, leading to the blurring of lines and further confusion.
Some business analysts are called data scientists and I have even known a graphic designer to be referred to as a data scientist because they deal with Microsoft Excel on a regular basis.
Data analysts and data insight analysts still work with data, but there are key differences between these roles and a data scientist. These analysts tend to apply statistical techniques to extract useful, actionable insights from data. They are also required to communicate these results back to shareholders in clear business language. They do not need coding experience other than being able to use statistical software such as SPSS, SAS and Minitab.
A data scientist also works with data and uses every statistical method in the book that a data analyst might use, but they then go a few steps further. A data scientist works to predict future outcomes, create seamless automation tasks using machine learning and develops their own algorithms for solving the problem at hand. They have enough coding knowledge to then integrate these systems into apps and other software.
For a data scientist, theoretical mathematics beyond calculus and statistics is a must. They are also required to have scripting and coding experience. Being able to code in R, Python, SQL and/or Java is required in most data science roles.
The below description describes a data scientist succinctly:
“Data Scientist (n.): Person who is better at statistics than any software engineer and better at software engineering than any statistician.” -Josh Wills
One thing that all of these roles have in common, is the need for business acumen. Every data-related role is required to have a level of domain knowledge to be able to translate the business problems into their own workflow and tackle them.
The unique value a data scientist provides for a business is the ability to connect two very different fields: science and business. This hybrid provides a business with a clearer vision of the future and a competitive advantage over traditional decision-making processes.
If you have any questions or would like to discuss how data science could help find solutions and insights for your business, then please get in touch.